Blog
Your resource for the latest AI earch strategies, industry insights, thought leadership, and GEO news
What’s new

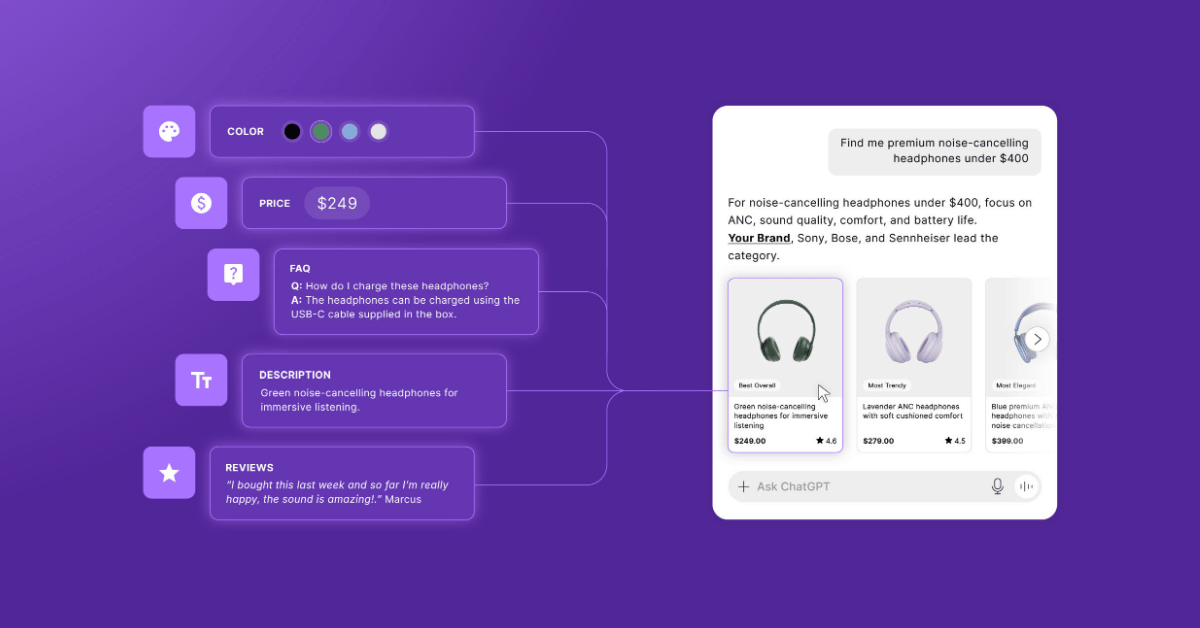

GET FRESH SEARCH INSIGHTS DELIVERED STRAIGHT TO YOUR INBOX
Browse all our blog posts
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
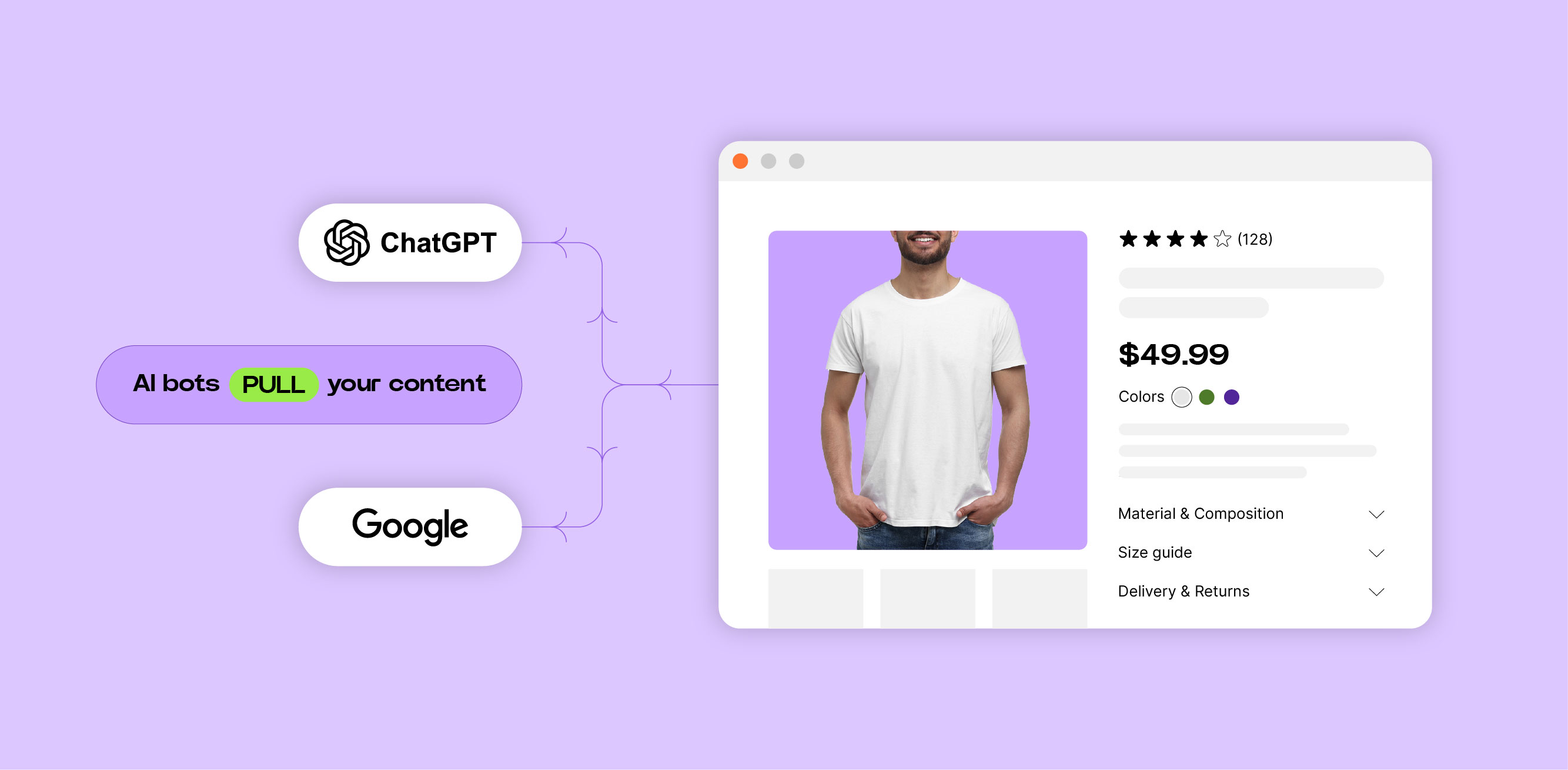

.png)

.png)





.png)
-Blogpost%20Header.png)
.png)
.jpg)
%20(1).png)







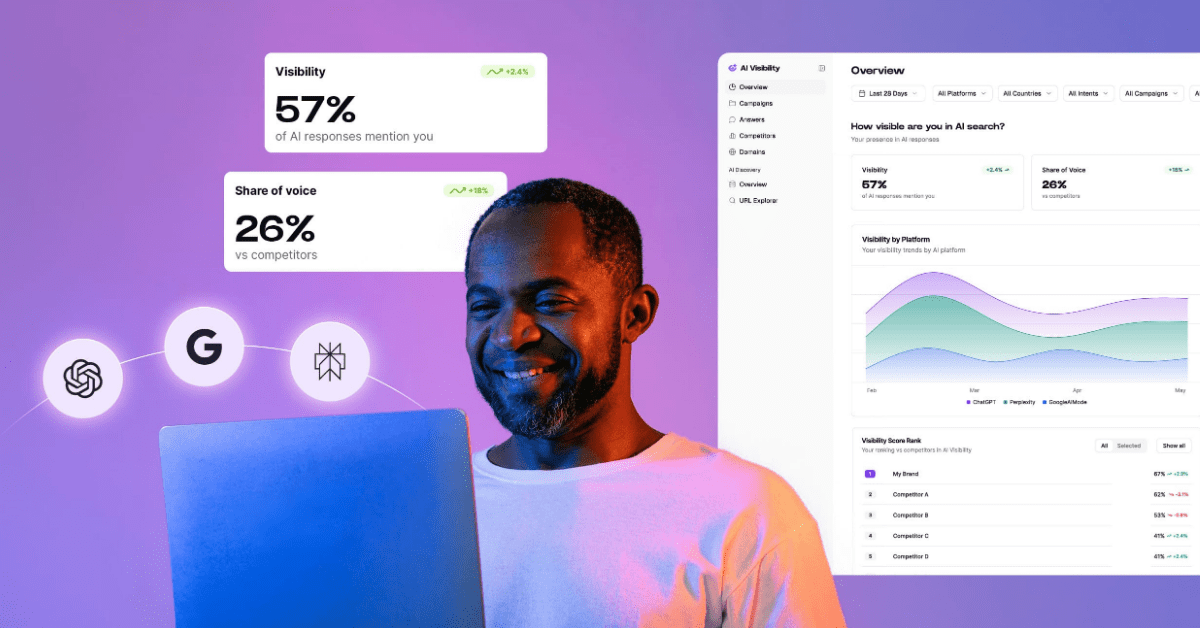




-min.png)

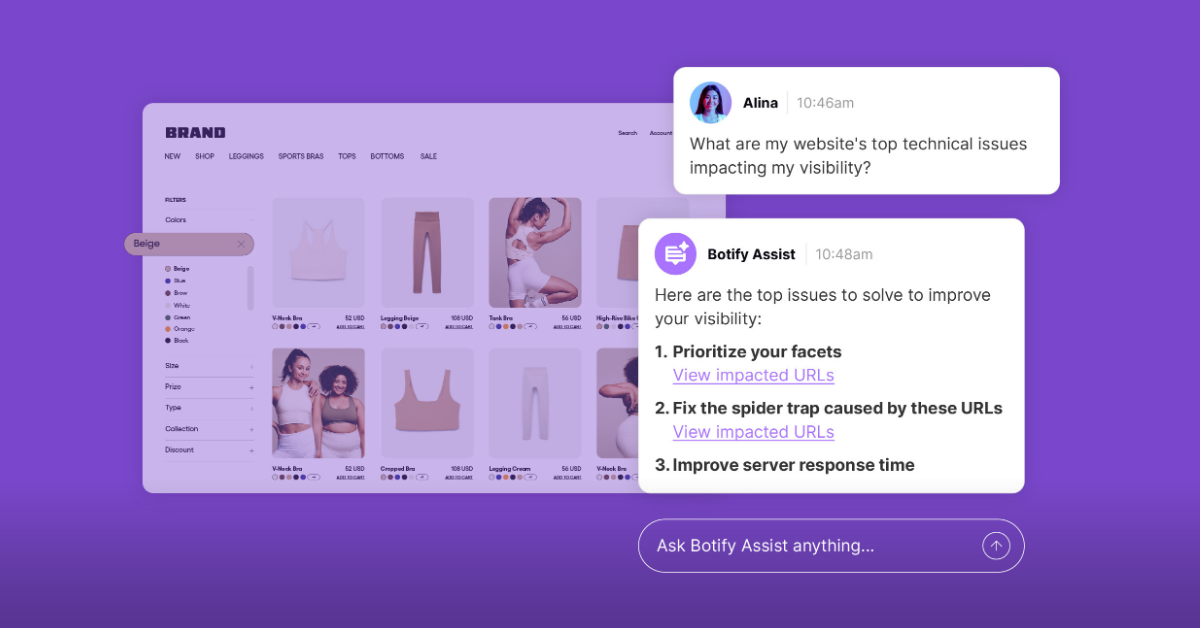





.jpg)









.jpg)





























































Botify Earns 2022 Great Place to Work Certification™
March 22, 2022
By
The Botify Team
READ MORE
.svg)
english











Botify Receives SaaS Growth Award from EY & Numeum
October 20, 2021
By
The Botify Team
READ MORE
english



How Do Core Web Vitals Impact The Full Marketing Team?
May 14, 2021
By
The Botify Team
READ MORE
english

Are Core Web Vitals and Page Experience The Same Thing?
May 7, 2021
By
The Botify Team
READ MORE
english



Seasonal SEO: How to Optimize Your E-Commerce Site
December 9, 2020
By
The Botify Team
READ MORE
english











































































Indexable URLs: The Mother Of All SEO Indicators
December 18, 2014
By
Annabelle Bouard
READ MORE
english

Do You Speak Russian? The Botify Logs Analyzer Does!
June 24, 2014
By
Annabelle Bouard
READ MORE
english






No items found.
No items found.
No items found.
No items found.
No items found.
No items to show
Join our newsletter
SEO moves fast. Stay up-to-date with a monthly digest of the industry’s best educational content, news and hot takes.
ENSURE THAT YOUR REVENUE-DRIVING PAGES ARE FOUND EVERYWHERE.
See botify in action

.svg)
.svg)
.svg)

