

.svg)


We've put together a checklist that walks through some simple steps to check the indexation status of your page or website, as well as ways to identify (and address) some of the most common issues that might be preventing your content from being indexed.
A comprehensive checklist for why your page isn't indexed by Google
This checklist serves as a troubleshooting flowchart - it is organized with the easiest, quickest checks and most common issues first, so hopefully you won't actually need to make your way through the entire thing to get your pages back on track to getting indexed.
Step 1: Check whether your page is showing up in the index
The first thing to check is to confirm that your page or website isn't already in the index. The quickest way to check this is with search operators. These are search queries that you can use in a Google search that help the searcher find more specific search results.
For example: use the operator "site:" to check indexation of an entire site:
site:domain.com
You can also use the same operator to check an individual page:
site:domain.com/page-name
If you see a result like this, it means your page is not currently in the index:
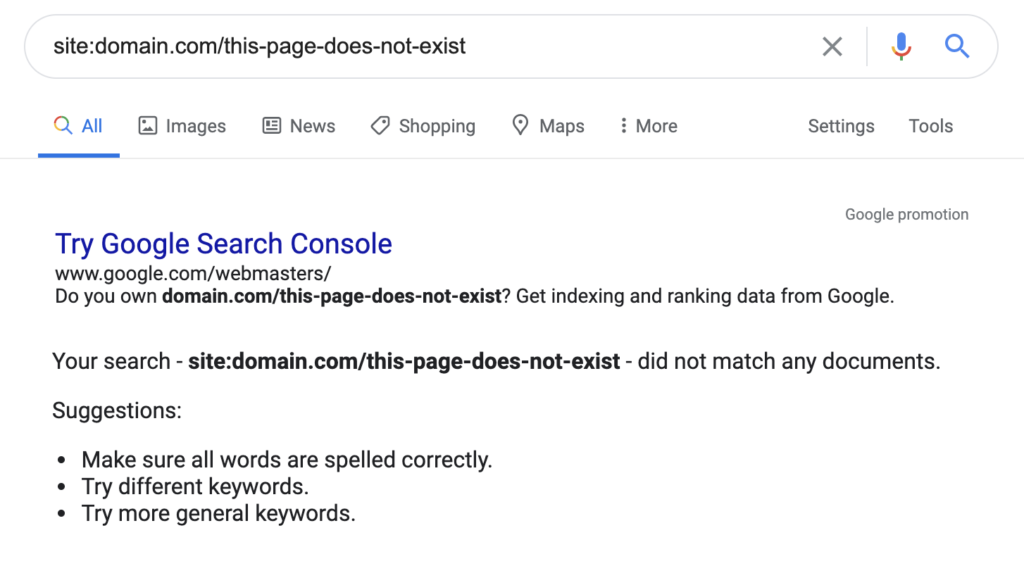
There are many more search operators, with a range of use cases, but this is the primary one you'll need for checking indexation.
How does Botify make it easy to see indexability?
While not a direct reflection of what Google does or does not have indexed, Botify makes it very easy to check, not just whether a page is Indexable, but the indexability of any group of pages, including:
- Page types / segmentation / shared URL structure
- Breadcrumbs
- Pages that share any commonalities in the HTML
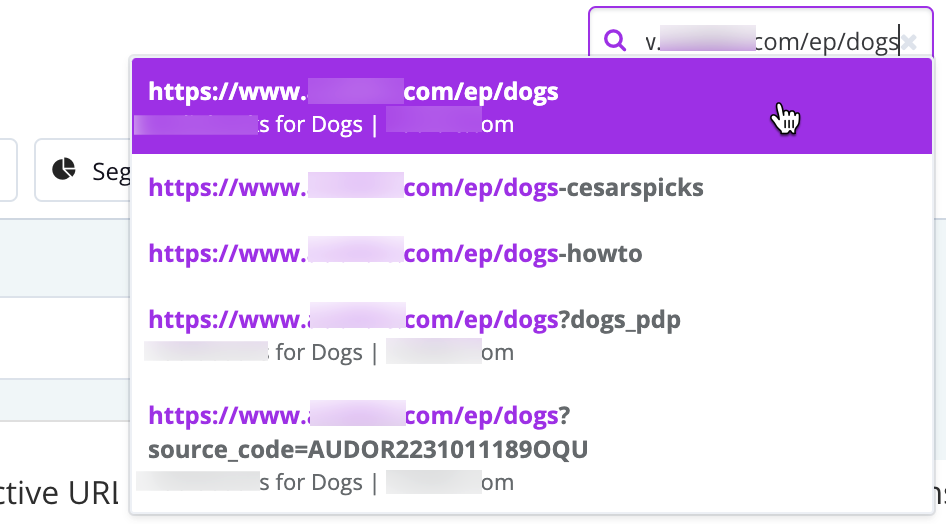
Click the links above to learn more about each breakdown available for crawl, log, and Google Search Console. For single URLs, it's as easy as doing a quick search in our URL explorer.
Step 2: Check Google Search Console for insights
The next place to check is Google Search Console. Head to the Coverage report for an overview of your site's indexation status:
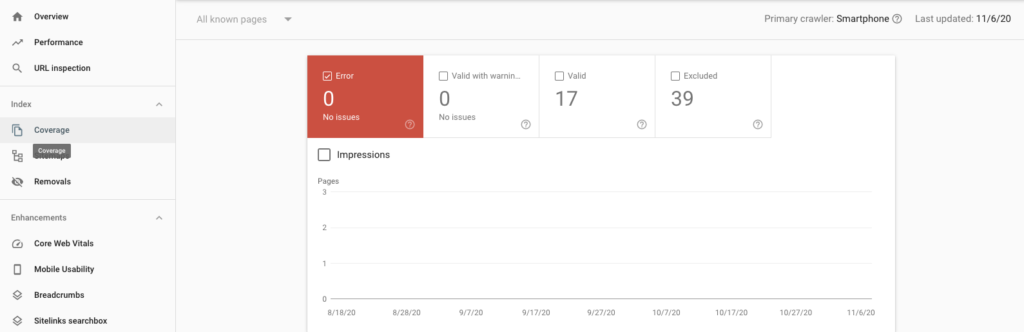
The two tabs that show pages which have not been indexed are the "error" tab and the "excluded" tab.
If your page was crawled and Google decided not to index it, it will be in the "Excluded" report.
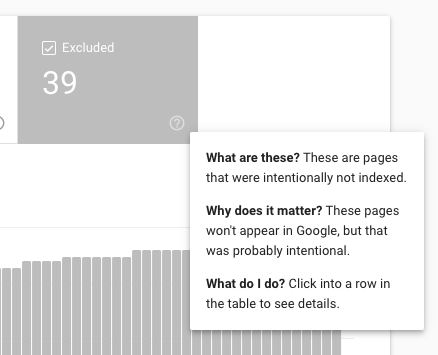
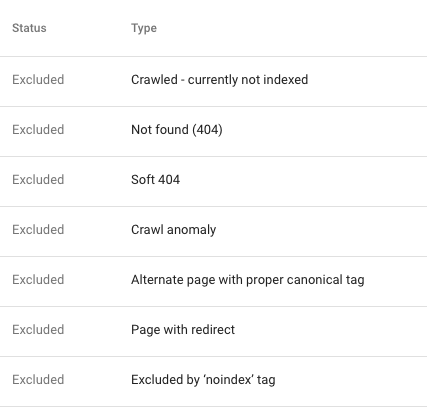
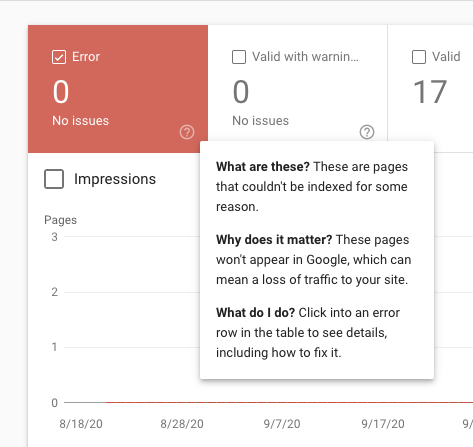
If your page could not be crawled and/or could not be indexed for some reason, it will appear in the "Error" report. It's worth noting there are more than 1K affected URLs, only a 1K sample will be available here - not necessarily the specific URL the user is looking for.
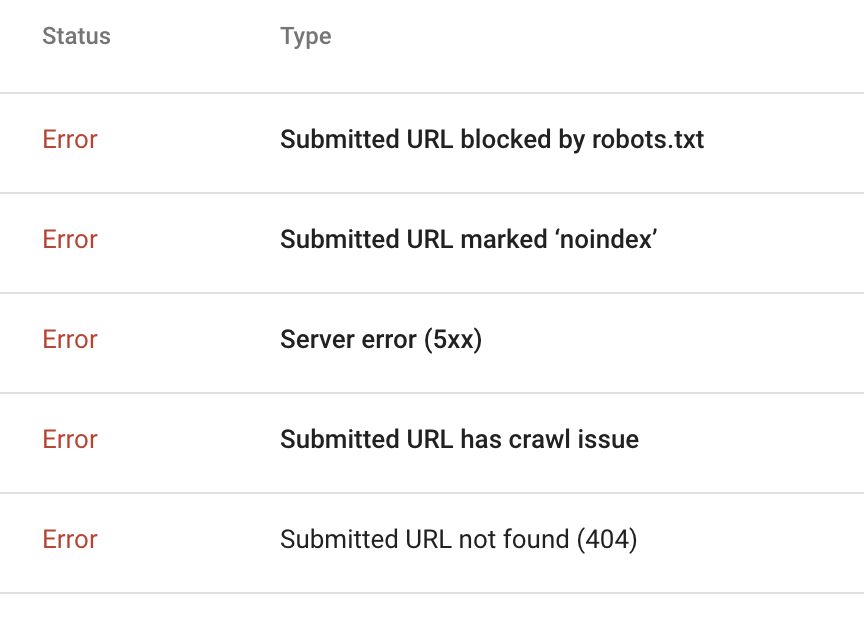
If your page appears in one of these reports, you should be able to tell what the issue is by clicking into that URL and selecting the "Inspect URL" option. This is a good initial go-to, or first place to check index status (vs the Coverage reports above which provide limited samples).


You can also choose to "Test Live URL" which can provide further information:

Depending on the size of your website, you may not be able to find the URL you're looking for in the Coverage report. These reports only provide up to 1000 "sample" URLs for each error type. Instead, you can also simply use the search bar at the top of the page to inspect the URL directly:

Step 3: Check for on page elements blocking indexation
The error reports may show that the pages are being blocked by a robots noindex meta tag ("Submitted URL marked 'noindex'"). To validate this issue, you can navigate directly to the page, and open the HTML page source code. (If you're not sure how to do this, simply add "view-source:" to the front of the full URL).
One you're viewing the source code, search the page for "noindex" and you'll be able to see whether there is a noindex tag blocking your page.

Your page may also have an X-Robots-Tag HTTP header, like this:
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
(…)
X-Robots-Tag: noindex
(…)
You can use a tool like this one to check your page's HTTP header.
If you have a Wordpress website, you may have accidentally set your privacy settings to "Ask search engines not to index this site". Simply update this setting to "Allow search engines to index this site."
Note - The Inspect URL tool will also flag if a page has a noindex directive.
Step 4: Check your robots.txt file
The other place that your page could be blocked by a robots directive is via the robots.txt file.
You can test this quickly using Google's robots.txt tester tool, or check the file yourself by going to /robots.txt on your domain.
Step 5: Check that your page is findable
In order for a page to be indexed, it has to be discovered by a crawler. There are a few ways that you might be preventing crawlers from discovering your page (and that you can leverage to ensure that they are able to find it).
If your page is not being linked to from somewhere else, or if it is linked to from an obscure part of the site, crawlers may not find the link and therefore may not be able to find the page. Make sure you include internal links on your site that point to the page if you want it to be accessed by search engines and indexed.
One of the best places to include the link to the page is in an XML sitemap. If your page is not included in the XML sitemap, Google may view the page as less valuable or simply may have a harder time finding it. To avoid this, be sure to include any pages which are important to get crawled and indexed in your XML sitemap.
Step 6: Check that your page works (even with Javascript turned off)
Even if your page is discovered by crawlers, it won't get indexed if the content can't be accessed. Make sure that your page:
- serves a 200 status code
- displays the important content and has clickable links even with Javascript disabled
If your website has frequent issues with downtime, this could also create issues with indexation.
Step 7: Check for duplicate or low value content
Google's goal is to show the most relevant content for a given query. Therefore, it devalues content that is too similar to other content that is already in the index.
Some of the ways that duplicate content can be generated include:
- parameters: if you use parameters, you may have multiple versions of the same page with different URLs
- facets / tag pages: if you use faceted navigation, or categorization like blog /tag/ pages, the content may be very similar if not duplicate across multiple tags or categories
- localization: city-specific pages or pages targeted for country / language combinations may have the same content and require more differentiation (or for international variants, the use of hreflang annotations)
- external duplication: if you are syndicating content from another source, scraping content or otherwise reposting something that's already been published, it will likely be viewed as duplicate (and doing too much of this can send a low quality content signal)
You should also check that there isn't a rel=canonical tag on the page pointing to a different URL as the primary version. You can check this via the "Inspect URL" tool in Google Search Console:
Or in the page source code by searching the code for 'rel=canonical':

Step 8: Check your site's .htaccess file
The .htaccess file is a server configuration file. It can be used to create redirects (and accidental redirect loops), rewrite ugly URL strings to cleaner versions, and even block pages from crawlers. If your site or page isn't blocked in robots.txt or via on-page directives like a noindex tag but isn't accessible to crawlers, it may be blocked via .htaccess.
Step 9: Check your site's load time
While having a slightly sluggish site won't do you any favors with Google, it typically won't prevent your content from being indexed (although it may hurt your ability to rank well). But if your page is regularly taking much longer than normal industry standards, especially if it takes so long to load that it's timing out, this could be viewed by search engines as a poor user experience and they may choose not to index this page. They may also simply not be able to access the content in that case.
Step 10: Check that your content is available on mobile devices
With mobile-first indexing becoming the prevalent (and soon, the only) method of indexation, crawlers may only see your content if it's available to mobile crawlers. Make sure that any content you want indexed is available on the mobile version of your website (and of course, that said mobile version is fast and user-friendly).
Step 11: Check yourself (also known as, "Could it be a penalty?")
If you've been dabbling in grey or black hat techniques which go against Google's guidelines, it is possible that you've been hit with a manual action. These are also known as "penalties", and happen when the Google team manually punishes a website for behavior and tactics they consider spammy.
These tactics include:
- unnatural links to or from your site
- hacked site
- thin content
- pure spam
- user generated spam
- cloaking and sneaky redirects
- cloaked images
- hidden text and keyword stuffing
- spammy free hosts
- AMP content mismatch
- sneaky mobile redirects
- spammy structured data markup
If you've been hit with a manual action, you should receive a notification in the Manual Actions report within Google Search Console. Typically this notification will include details on what the issue is and recommended actions for how it can be fixed. Once all affected pages have been fixed, you'll need to submit a review request from within the report.
Submitting your page for indexation
Once you've checked all of these items and addressed any of the issues you find, you may want to (re-)submit your page to Google for crawling. Currently this feature is temporarily unavailable but typically you can do this from Google Search Console by using the "Inspect URL" feature and then selecting "Request Indexing".
You can also submit your XML sitemap for crawling via Google Search Console if you've made updates or created a new sitemap.
The Checklist
- Check whether your page is showing up in the index
- Check Google Search Console for insights
- Check for on page elements such as a noindex tag
- Check your robots.txt file
- Check that your page is findable
- Check that your page works (even with Javascript turned off!)
- Check for duplicate content
- Check your .htaccess file
- Check your site's load time
- Check that your content is available on mobile devices
- Check yourself (could it be a penalty?)
- (Re)submit your page for indexation


.svg)


.svg)
.svg)
