3 Takeaways From Our Webinar on Page Experience
Indexing
Technical SEO



When I saw the number of URLs on HubSpot’s site Google had excluded from the index, I blinked and thought, “Well, that can’t be right.”
As part of some routine health checks, I was reviewing our index coverage report in Google Search Console.
The count of affected pages seemed pretty reasonable for redirect errors, 404s, and soft 404s. But “Alternate page with proper canonical tag”? That number seemed completely unreasonable.
According to the report, more than 10.5 million pages on our site were currently deindexed.
HubSpot’s English site doesn’t‚ well, shouldn’t‚ have anywhere near that many pages.
What was going on?
When I double-clicked to see which pages were being excluded, the culprit was immediately clear. The same URL path showed up in every line:
https://www.hubspot.com/agencies
This directory lists agencies and service providers (some of which sell HubSpot-related services, some of which do not).
Like any content directory with multiple categories and thousands of items, it’s pretty big. Think of an e-commerce site: if you’ve got 3+ categories (men’s, women’s, kids), and 20+ sub-categories (shirts, pants, skirts, dresses, accessories, shoes, etc.), and tens to hundreds of products in each sub-category, very quickly you’re looking at a large number of pages.
But our directory hadn’t always been set up this way. We used to rely on parameter URLs to create “filtered” results.
For example, if a user-selected “Content creation” from the Services drop-down menu and “Australia” from the Location menu, the page would have reloaded and the URL would’ve been appended with their choices:
https://www.hubspot.com/agencies?services=content-creation&location=Australia
From the user’s perspective, this works just fine. From Googlebot’s perspective, however, nothing about the content changes when the categories are applied. It’s essentially the same page‚ just with some objects hidden.
That means pages can’t rank for any of the tens of thousands of short, medium, and long-tail queries they should be able to. In our case, our pages should have been showing up for everything from “best advertising agencies” and “social media services for non-profit in New York,” but they weren’t.
To begin capturing all of this traffic, the team moved the directory from parameter URLs to static URLs. Now, selecting an industry, service, and/or location would cause a hard-refresh and a new, indexable page, e.g. https://www.hubspot.com/agencies/social-media/non-profit/united-states/new-york.
Great, right? Except seeing that 10.5 million URLs were currently deindexed gave me the sinking feeling something had gone wrong.
I did some quick napkin math. 350 locations x 30 services x 25 industries equaled‚ 262,500 unique combinations, and therefore 262,500 possible URLs.
How were we getting to 10.5 million? The math literally didn’t add up.
And why was this so bad, anyway? A few reasons.
99.99% of the directory’s pages weren’t indexed, which meant:
We need to address this issue‚ not only for the sake of the Services Directory, but for the entire HubSpot website.
First, I went to Botify. HubSpot’s head of technical SEO, Victor Pan, had actually removed the Services Directory from our crawl (using the virtual robots.txt option in Advanced Settings) because he knew it would swallow up our entire crawl budget.
So I ran a separate crawl just for https://www.hubspot.com/agencies.
The results were illuminating, to say the least.
First, in the URL explorer report, I noticed hundreds of URLs using the old parameter structure instead of the new static URLs. These should redirect to the correct ones, but according to Botify, their HTTP status codes were 200.
In other words: not only had the migration to static filter pages created hundreds of thousands of new URLs, but all of the old parameter URLs were still active.
And on top of that, many of the other URLs serving up 200s were wrong. Our static URLs always followed a specific hierarchy:
agencies/(service)/(industry)/(location)
Whenever you’re automatically creating a large number of pages, you should always create URL logic. That way, you won’t have tons of pages with different strings but duplicate content.
However, it looked like our rules weren’t working (or maybe had never existed!).
I found URLs with location first, then service, then industry, or service, followed by location, followed by industry. I tried out a few random URLs in my browser, purposely messing up the proper order. All the pages loaded.
It looked like our system would accept virtually any combination of categories in any order. I didn’t want to do the math to know how many potential URLs that meant‚ it was definitely multiple million.
This was clearly a bigger problem than I’d anticipated.
Yet whether you work in-house or at an agency, recognizing an issue or opportunity is only half the battle.
Next, you need to help the stakeholders understand the scope of the situation, its implications, and what they should do about it.
In this case, I needed to work with the Partner Marketing team, who runs the Services Directory program. They decide which changes are made to the directory and when.
They had built out the directory roadmap for the next several months; it was my job to not only get on the roadmap, but get right to the top.
I’d already written a summary of the situation for my boss, but I knew it wouldn’t resonate with the Partner Marketing team. Too much jargon.
So I completely rewrote the memo, challenging myself to use zero technical SEO terms. Basically, I wanted any random HubSpotter to be capable of reading my brief and immediately wrapping their head around the problem. It was called, “Why Aren’t Service Pages Showing Up in Google?”
After explaining the cause, I laid out my recommendations.
The Partner Marketing team decided to follow all of them.
Our top priority was ensuring only URLs that followed the correct hierarchy would successfully load. After that was in place, we could address the thin/duplicate content issues.
According to Botify’s Content Quality report, most of our pages had far more “template” than “content.” In general, you want the opposite: more content than template. When Google evaluates a page’s quality, it essentially ignores everything that’s not unique content.
I added this visual to my report to drive home just how little non-templated content was on each listing page:
Because there was so little unique content, Googlebot was grouping together pages with different intent and arbitrarily choosing a canonical (which is why so many pages had the “Alternate page with proper canonical tag” error).
Here’s a snapshot from the Similarities/Duplicates section of our Content Quality report:
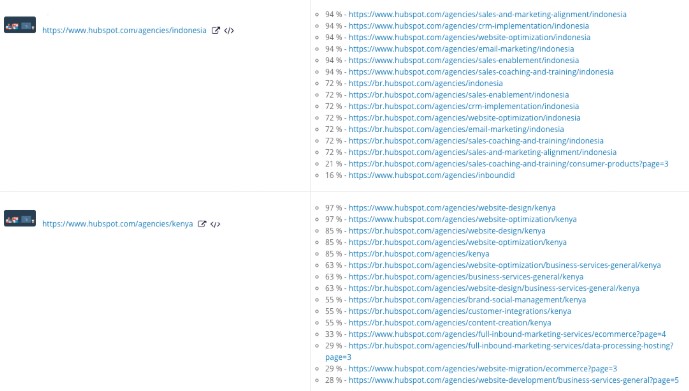
To address this issue, we made the headers (and title tags) of each filter page dynamic. Previously every page had the same header: “Get help from a certified agency or consultant.”
Obviously, identical headers weren’t helping Google‚ or our visitors‚ differentiate between different pages. So I wrote seven different header templates (for every combination of industry, service, and location). Our developer, Nhori Lopchan Tamang, configured the headers so they’d pull an up-to-date count of the items in that combination of filters (a la Pinterest).

Not only did this change add important signals for Googlebot, it also improved CTR from the SERP.
Next, Nhori changed the default number of cards per page from 15 to 45. Just like that, the amount of unique on-page content tripled. (As an added benefit, our max page depth went from 243 to 82. Still far less flat than I’d like, but it was progress.)
The Partner Marketing team had already been planning to limit the number of industries an agency added to their profile. At the time, each agency could mark itself as serving every single industry‚ more than 30. Many agencies did to maximize the number of categories they appeared in‚ which meant there were hundreds of pages with different combinations of industry, service, and location that nonetheless had near-identical content.
After the new five-industry cap, the category page results became far more diverse (which not only helped us from a technical perspective, but provided a better user experience.)
To cut down on the number of pages with thin content, Victor and Nhori adjusted our noindex rule. Previously, any page with one result or fewer was automatically no-indexed. They bumped it up to three‚ which impacted tens of thousands of pages.
So, what were the results?
The number of affected pages with the “Alternate page with proper canonical tag” error type dropped by 90%‚ and now, none of them are /agencies URLs.
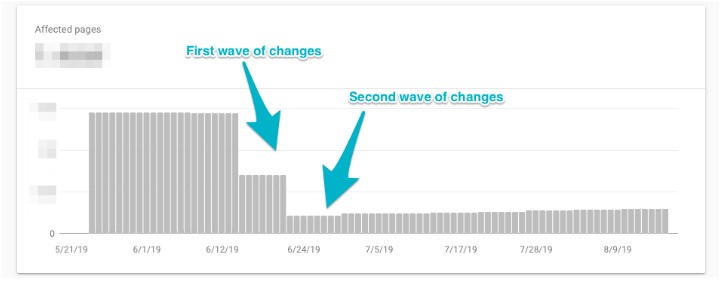
The directory just had a record month of traffic, completely defying seasonal trends. And the coolest part about this project? We’ve achieved these results solely through technical changes. We didn’t rewrite, add, or cut any content. We didn’t give the directory a slick new interface. We didn’t add new media types or schema mark-up. (Not that I wouldn’t love to make those changes, too!)
It’s an important reminder that technical SEO is just as important as content SEO.



Sign up for our monthly newsletter.




